HNSW:使用分层可导航小世界图进行高效且稳健的近似最近邻搜索
Efficient and robust approximate nearest
neighbor search using Hierarchical Navigable
Small World graphs
https://arxiv.org/pdf/1603.09320
摘要
— 我们提出了一种基于可控层次导航小世界图(分层NSW,HNSW)的近似K-近邻搜索新方法。所提出的解决方案完全基于图,无需在粗搜索阶段使用额外的搜索结构,而这些结构通常用于大多数邻近图技术中。分层NSW增量地构建了一个多层结构,由存储元素嵌套子集的层次邻近图(层)组成。元素出现的最大层是随机选择的,具有指数衰减的概率分布。这使得生成的图类似于之前研究的导航小世界(NSW)结构,同时还能按特征距离尺度分离链接。从上层开始搜索,并利用尺度分离,与NSW相比可以提高性能,并实现对数复杂度扩展。额外使用选择邻近图邻居的启发式方法,显著提高了高召回率和高度聚类数据情况下的性能。性能评估表明,所提出的通用度量空间搜索索引能够大大超越之前开源的最先进的仅向量方法。该算法与跳跃列表结构的相似性允许直接平衡分布式实现。
索引术语
— 图和树搜索策略、人工智能、信息搜索与检索、信息存储与检索、信息技术与系统、搜索过程、图与网络、数据结构、最近邻搜索、大数据、近似搜索、相似性搜索
1 引言
不断增长的可用信息资源已经导致对可扩展和高效的相似性搜索数据结构需求的增加。信息搜索中普遍使用的方法之一是K-近邻搜索(K-NNS)。K-NNS假设你已经定义了数据元素之间的距离函数,并旨在从数据集中找到K个与给定查询距离最小的元素。这类算法被应用于许多场景,如非参数机器学习算法、大规模数据库中的图像特征匹配[1]和语义文档检索[2]。K-NNS的简单方法是计算查询与数据集中每个元素之间的距离,然后选择距离最小的元素。不幸的是,这种简单方法的复杂度与存储元素的数量呈线性关系,使其在大规模数据集上不可行。这导致了对快速且可扩展的K-NNS算法的高度关注。
由于"维度灾难",K-NNS的精确解决方案[3-5]只能在相对低维数据情况下提供显著的搜索加速。为了克服这个问题,提出了近似最近邻搜索(K-ANNS)的概念,它通过允许少量错误来放宽精确搜索的条件。非精确搜索的质量(召回率)被定义为找到的真正最近邻数量与K的比率。最流行的K-ANNS解决方案基于树算法的近似版本[6, 7]、局部敏感哈希(LSH)[8, 9]和产品量化(PQ)[10-17]。基于邻近图的K-ANNS算法[10, 18-26]最近变得流行,在高维数据集上提供了更好的性能。然而,邻近图路由的幂律扩展在低维或聚类数据的情况下会导致性能严重下降。
在本文中,我们提出了分层可导航小世界(Hierarchical NSW,HNSW),这是一种新的完全基于图的增量K-ANNS结构,它能提供更好的对数复杂度扩展。主要贡献包括:图的入口节点的显式选择、按不同尺度分离链接以及使用高级启发式方法选择邻居。另外,Hierarchical NSW算法也可以被视为概率跳跃列表结构[27]的扩展,用邻近图替代链表。性能评估表明,所提出的通用度量空间方法能够大大超越之前只适用于向量空间的开源最先进方法。
2 相关工作
2.1 邻近图技术
在绝大多数研究的图算法中,搜索采用k-最近邻(k-NN)图的贪婪路由形式[10, 18-26]。对于给定的邻近图,我们从某个入口点开始搜索(可以是随机的或由单独算法提供),并迭代地遍历图。在遍历的每一步,算法检查查询与当前基础节点的邻居之间的距离,然后选择使距离最小化的相邻节点作为下一个基础节点,同时持续跟踪已发现的最佳邻居。当满足某些停止条件(例如距离计算的数量)时,搜索终止。k-NN图中到最近邻居的链接作为Delaunay图[25, 26]的简单近似(Delaunay图保证基本贪婪图遍历的结果始终是最近邻)。不幸的是,如果没有关于空间结构的先验信息[4],无法高效构建Delaunay图,但可以通过仅使用存储元素之间的距离来通过最近邻实现其近似。已经证明,使用这种近似的邻近图方法与其他k-ANNS技术(如kd树或LSH)相比具有竞争力[18-26]。
k-NN图方法的主要缺点是:1)路由过程中步数与数据集大小呈幂律扩展[28, 29];2)可能丧失全局连通性,导致在聚类数据上搜索结果较差。为了克服这些问题,提出了许多混合方法,这些方法使用仅适用于向量数据的辅助算法(如kd树[18, 19]和产品量化[10])通过粗搜索找到更好的入口节点候选。
在[25, 26, 30]中,作者提出了一种称为可导航小世界(NSW,也称为度量化小世界,MSW)的邻近图K-ANNS算法,该算法利用可导航图,即贪婪遍历中的跳数与网络大小相比呈对数或多项式对数扩展的图[31, 32]。NSW图通过随机顺序连续插入元素构建,将它们与先前插入元素中的M个最近邻双向连接。M个最近邻通过结构的搜索过程(从多个随机入口节点进行贪婪搜索的变体)找到。在构建开始阶段插入的元素的最近邻链接,后来成为网络枢纽之间的桥梁,保持整体图的连通性并允许贪婪路由过程中跳数的对数扩展。
NSW结构的构建阶段可以在没有全局同步且不影响精度的情况下有效并行化[26],是分布式搜索系统的良好选择。NSW方法在某些数据集上提供了最先进的性能[33, 34],然而,由于整体多项式对数复杂度扩展,该算法在低维数据集上仍然容易严重性能下降(在这些数据集上,NSW可能比基于树的算法慢几个数量级[34])。
2.2 可导航小世界模型
贪婪图路由呈对数或多项式对数扩展的网络被称为可导航小世界网络[31, 32]。这类网络是复杂网络理论的重要课题,旨在理解现实生活网络形成的潜在机制,以便将其应用于可扩展路由[32, 35, 36]和分布式相似性搜索[25, 26, 30, 37-40]应用。
考虑可导航网络空间模型的首批工作是由J. Kleinberg[31, 41]完成的,作为著名的Milgram实验[42]的社交网络模型。Kleinberg研究了Watts-Strogatz随机网络[43]的一个变体,在d维向量空间中使用规则格子图,同时增加遵循特定长链接长度分布r-α的长程链接。对于α=d,通过贪婪路由到达目标的跳数呈多项式对数扩展(而对于任何其他α值则为幂律)。这一思想启发了许多基于导航效应的K-NNS和K-ANNS算法的发展[37-40]。但即使Kleinberg的可导航性标准原则上可以扩展到更一般的空间,为了构建这样一个可导航网络,必须预先了解数据分布。此外,Kleinberg图中的贪婪路由最好也只能达到多项式对数复杂度可扩展性。
另一个著名的可导航网络类别是无标度模型[32, 35, 36],它可以再现现实网络的几个特征,并被推广用于路由应用[35]。然而,由这类模型产生的网络在贪婪搜索中具有更糟糕的幂律复杂度扩展[44],而且,与Kleinberg模型一样,无标度模型需要对数据分布的全局知识,使其不适用于搜索应用。
上述NSW算法使用一种更简单的、以前未知的可导航网络模型,允许去中心化图构建,适用于任意空间中的数据。有人认为[44],NSW网络形成机制可能负责大规模生物神经网络的可导航性(其存在有争议):类似模型能够描述小型大脑网络的生长,同时该模型预测了大规模神经网络中观察到的几个高级特征。然而,NSW模型也受到路由过程中多项式对数搜索复杂度的限制。
2.3 分层可导航小世界(HNSW)的动机
通过分析路由过程,可以确定提高NSW搜索复杂度的方法,这在[32, 44]中已有详细研究。路由过程可分为"放大"和"缩小"两个阶段[32]。贪婪算法从低度节点开始"放大"阶段,同时遍历图并增加节点的度数,直到节点链接长度的特征半径达到与查询距离相当的尺度。在后者发生之前,节点的平均度数可能保持相对较小,这增加了陷入远距离虚假局部最小值的概率。
可以通过从最大度数的节点开始搜索(NSW结构中最先插入的节点是很好的候选者[44])来避免NSW中描述的问题,直接进入搜索的"缩小"阶段。测试表明,将枢纽设为起点大大提高了结构中成功路由的概率,并在低维数据上提供了显著更好的性能。然而,它在最佳情况下仍然只有单个贪婪搜索的多项式对数复杂度可扩展性,并且与分层NSW相比,在高维数据上表现更差。
NSW中单个贪婪搜索具有多项式对数复杂度扩展的原因是,总的距离计算次数大致与贪婪算法跳数的平均数乘以贪婪路径上节点的平均度数成正比。平均跳数呈对数缩放[26, 44],而贪婪路径上节点的平均度数也呈对数缩放,这是因为:1)随着网络增长,贪婪搜索倾向于通过相同的枢纽[32, 44];2)枢纽连接的平均数量随着网络规模的增加而对数增长。因此,我们得到了复杂度的整体多项式对数依赖关系。
分层NSW算法的理念是根据链接的长度尺度将它们分为不同层,然后在多层图中搜索。在这种情况下,我们可以只评估每个元素所需的固定部分连接,与网络大小无关,从而实现对数可扩展性。在这种结构中,搜索从只有最长链接的上层开始(即"缩小"阶段)。算法贪婪地遍历上层元素,直到达到局部最小值(见图1说明)。之后,搜索切换到下层(具有较短链接),从上一层局部最小值的元素重新开始,过程重复。所有层中每个元素的最大连接数可以设为常数,从而实现导航小世界网络中路由的对数复杂度扩展。
形成这种分层结构的一种方法是通过引入层来显式设置具有不同长度尺度的链接。对于每个元素,我们选择一个整数级别l,它定义了该元素所属的最大层。对于层中的所有元素,增量构建邻近图(即仅包含近似Delaunay图的"短"链接的图)。如果我们设置l的指数衰减概率(即遵循几何分布),我们可以得到结构中预期层数的对数缩放。搜索过程是从顶层开始、在零层结束的迭代贪婪搜索。
如果我们合并所有层的连接,该结构变得类似于NSW图(在这种情况下,l可以与NSW中的节点度数对应)。与NSW不同,分层NSW构建算法不要求在插入前对元素进行洗牌 - 随机性是通过使用层次随机化实现的,因此即使在数据分布暂时变化的情况下也允许真正增量索引(尽管由于只有部分确定性的构建过程,改变插入顺序会略微改变性能)。
分层NSW的理念也与众所周知的一维概率跳跃列表结构[27]非常相似,可以使用其术语来描述。与跳跃列表的主要区别是,我们通过用邻近图替代链表来泛化结构。因此,分层NSW方法可以利用相同的方法来创建分布式近似搜索/覆盖结构[45]。
在元素插入过程中选择邻近图连接时,我们使用一种启发式方法,该方法考虑候选元素之间的距离来创建多样化连接(空间近似树[4]使用类似的算法来选择树子节点),而不仅仅是选择最近的邻居。该启发式方法从最近(相对于插入的元素)的候选者开始检查,并仅当候选者比任何已连接的候选者更接近基础(插入的)元素时才创建连接(详见第4节)。
当候选数量足够大时,该启发式方法允许获得相对邻近图[46]作为子图,这是通过仅使用节点之间的距离可推导出的Delaunay图的最小子图。相对邻近图允许轻松保持全局连通分量,即使在高度聚类数据的情况下(见图2说明)。请注意,该启发式方法创建了与精确相对邻近图相比的额外边,允许控制对搜索性能很重要的连接数量。对于一维数据,该启发式方法允许仅使用有关元素之间距离的信息来获得精确的Delaunay子图(在这种情况下与相对邻近图一致),从而实现从分层NSW到一维概率跳跃列表算法的直接过渡。
分层NSW邻近图的基本变体也在文献[18]中使用(称为"稀疏邻近图")用于邻近图搜索。类似的启发式方法也是FANNG算法的重点[(在当前手稿的第一个版本发布后不久发表),具有略微不同的解释,基于稀疏n
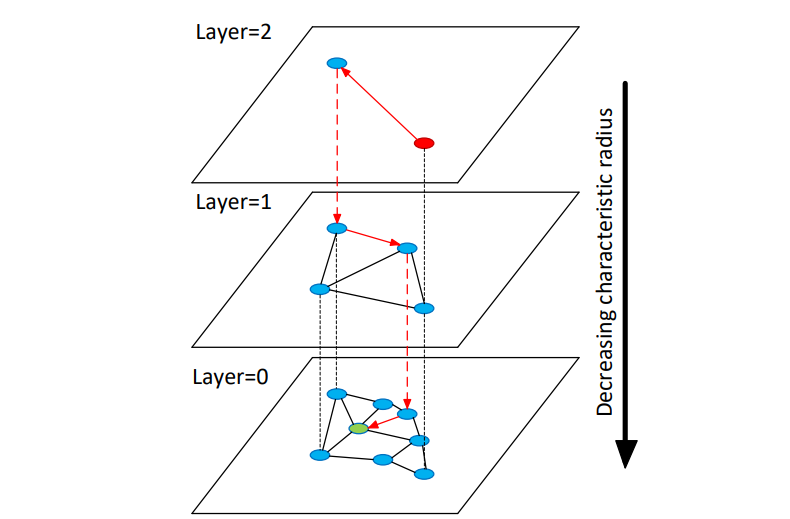
**图1. 分层NSW理念的说明。**搜索从顶层的一个元素(显示为红色)开始。红色箭头显示了贪婪算法从入口点到查询(显示为绿色)的方向。

**图2. 用于选择两个孤立簇的图邻居的启发式方法的说明。**在簇1的边界上插入了一个新元素。该元素的所有最近邻居都属于簇1,因此缺少簇之间Delaunay图的边缘。然而,该启发式方法从簇2中选择元素e2,从而在插入元素相对于簇1的任何其他元素来说是最接近e2的情况下维持全局连通性。
4 算法描述
网络构建算法(算法1)通过连续将存储的元素插入到图结构中来组织。对于每个插入的元素,会随机选择一个整数最大层级 l,其概率分布呈指数衰减(由 mL 参数标准化,见算法1中第4行)。
插入过程的第一阶段从顶层开始,通过贪婪遍历图来找到该层中距离插入元素 q 最近的 ef 个邻居。之后,算法使用前一层找到的最近邻居作为入口点继续在下一层进行搜索,过程重复进行。每一层的最近邻居是通过算法2中描述的贪婪搜索算法的变体找到的,这是[26]中算法的更新版本。要在某层 l 中获取近似 ef 个最近邻居,在搜索过程中会维护一个动态列表 W,包含 ef 个找到的最近元素(初始填充入口点)。通过评估列表中最近的、之前未评估过的元素的邻域来更新列表,直到列表中每个元素的邻域都被评估过。与限制距离计算次数相比,分层NSW的停止条件具有优势 - 它允许丢弃比列表中最远元素更远的评估候选项,从而避免搜索结构膨胀。与NSW一样,为了更好的性能,该列表通过两个优先队列来模拟。与NSW的区别(以及一些队列优化)是:1)入口点是固定参数;2)不是改变多重搜索的数量,而是通过不同的参数 ef 来控制搜索质量(在NSW [26]中设置为 K)
在搜索的第一阶段,ef参数设置为1(简单贪婪搜索)以避免引入额外参数。当搜索达到小于或等于l的层时,构建算法的第二阶段开始。第二阶段有两点不同:1)ef参数从1增加到efConstruction,以控制贪婪搜索过程的召回率;2)在每一层找到的最近邻居也被用作插入元素连接的候选者。
考虑了两种从候选者中选择M个邻居的方法:简单连接到最近元素(算法3)以及考虑非常短的贪婪算法路径的启发式方法(算法4),如第3节所述。令人惊讶的是,将mL从零增加会导致非常高维数据的速度明显提高(10万个密集随机d=1024向量,见图4),并且不会对分层NSW方法带来任何惩罚。对于如SIFT向量[1](具有复杂混合结构)这样的真实数据,增加mL的性能改进更高,但在当前设置下与启发式方法带来的改进相比不那么明显(见图5,在BIGANN[13]学习集的500万个128维SIFT向量上的1-NN搜索性能)。
Mmax0(元素在零层可以拥有的最大连接数)的选择也对搜索性能有很强的影响,尤其是在高质量(高召回率)搜索的情况下。模拟表明,将Mmax0设置为M(如果不使用邻居选择启发式,这对应于每层上的kNN图)会在高召回率时导致非常强烈的性能惩罚。模拟还表明,2·M是Mmax0的一个好选择:将参数设置更高会导致性能下降和过度的内存使用。图6展示了500万SIFT学习数据集的搜索性能结果,取决于Mmax0参数(在Intel Core i5 2400 CPU上完成)。建议值在不同召回率下提供接近最优的性能。
在所有考虑的情况中,使用邻近图邻居选择的启发式方法(算法4)与简单连接到最近邻居(算法3)相比,导致更高或相似的搜索性能。对于低维数据、中维数据的高召回率以及高度聚类数据的情况,效果最为明显(从理念上讲,不连续性可以被视为局部低维特征),见图7的比较(Core i5 2400 CPU)。当使用最近邻居作为邻近图的连接时,分层NSW算法无法为聚类数据实现高召回率,因为搜索会卡在簇的边界。相反,当使用启发式方法(以及候选扩展,算法4中的第3行)时,聚类甚至会导致更高的性能。对于均匀和非常高维的数据,邻居选择方法之间几乎没有差异(见图4),可能是因为在这种情况下,几乎所有最近邻居都被启发式方法选中。
留给用户的唯一有意义的构建参数是M。M的合理范围是从5到48。模拟表明,较小的M通常在较低的召回率和/或较低维度数据中产生更好的结果,而较大的M在高召回率和/或高维度数据中表现更好(见图8说明,Core i5 2400 CPU)。该参数还定义了算法的内存消耗(与M成正比),因此应谨慎选择。
efConstruction参数的选择很直接。如[26]中所建议,它必须足够大以在构建过程中产生接近1的K-ANNS召回率(对于大多数用例,0.95已足够)。和[26]一样,这个参数可能会影响候选元素之间的距离,以创建不同方向的连接(算法4),如第3节所述。该启发式方法有两个额外参数:extendCandidates(默认设置为false),它扩展了候选集并且仅对极度聚类的数据有用,以及keepPrunedConnections,它允许每个元素获得固定数量的连接。元素在每层可以拥有的最大连接数由每个高于零的层的参数Mmax定义(地面层单独使用特殊参数Mmax0)。如果节点在建立新连接时已经满了,则其扩展连接列表会被用于邻居选择的相同算法(算法3或4)缩减。
当插入元素在零层上建立连接后,插入程序终止。
分层NSW中使用的K-ANNS搜索算法在算法5中介绍。它大致等同于层级l=0的项的插入算法。区别在于,在地面层找到的最近邻居用作连接的候选者,现在作为搜索结果返回。搜索质量由ef参数控制(对应于构建算法中的efConstruction)。
4.1 构建参数的影响
算法构建参数mL和Mmax0负责维护构建图中的小世界导航性。将mL设置为零(这对应于图中的单层)并将Mmax0设置为M会导致产生定向k-NN图,具有之前研究过的幂律搜索复杂度[21, 29](假设使用算法3进行邻居选择)。将mL设置为零并将Mmax0设置为无穷大会导致产生具有多对数复杂度的NSW图[25, 26]。最后,将mL设置为某个非零值会导致可控层次图的出现,通过引入层来实现对数搜索复杂度(见第3节)。
为了实现可控层次的最佳性能优势,不同层上邻居之间的重叠(即也属于其他层的元素邻居百分比)必须很小。为了减少重叠,我们需要减少mL。然而,同时,减少mL会导致每层贪婪搜索期间平均跳数的增加,这会对性能产生负面影响。这导致mL参数存在最优值。
mL的简单选择是1/ln(M),这对应于跳跃列表参数p=1/M,层之间平均单元素重叠。在Intel Core i7 5930K CPU上进行的模拟表明,所提出的mL选择是合理的(见图3,1000万个随机d=4向量的数据)。此外,该图显示了在低维数据上将mL从零增加时的巨大加速,以及使用启发式方法选择图连接的效果。
很难期望高维数据有相同的行为,因为在这种情况下,k-NN图已经具有可以通过使用样本数据进行自动配置。构建过程可以轻松高效地并行化,只需很少的同步点(如图9所示),且对索引质量没有明显影响。构建速度/索引质量的权衡通过efConstruction参数控制。搜索时间和索引构建时间之间的权衡在图10中针对1000万SIFT数据集进行了展示,表明在4X 2.4 GHz 10核Xeon E5-4650 v2 CPU服务器上,只需3分钟就能以efConstruction=100构建出合理质量的索引。进一步增加efConstruction只会带来很少的额外性能提升,但会显著延长构建时间。
4.2 复杂度分析
4.2.1 搜索复杂度
搜索的复杂度可以在假设我们构建精确德劳内图而非近似图的情况下进行严格分析。假设我们已在某层找到了最近元素(通过德劳内图保证),然后下降到下一层。可以证明,在该层找到最近元素之前的平均步数受常数限制。
实际上,层与数据元素的空间位置无关,因此,当我们遍历图时,下一个节点属于上层的固定概率p=exp(-mL)。然而,层内搜索总是在到达属于更高层的元素之前终止(否则上层搜索会在不同元素上停止),因此在第s步未达到目标的概率受exp(-s·mL)限制。因此,一层内的预期步数受几何级数和S=1/(1-exp(-mL))限制,这与数据集大小无关。
如果假设在大数据集极限情况下,德劳内图中节点的平均度数被常数C限制(这适用于随机欧几里得数据[48],但可能在特殊空间中被违反),则一层内的总平均距离计算次数受常数C·S限制,与数据集大小无关。
由于最大层索引的期望值按构造比例为O(log(N)),整体复杂度为O(log(N)),这与低维数据集的模拟结果一致。
在分层NSW中,由于使用了具有固定每元素邻居数的近似边选择启发式方法,最初假设的精确德劳内图被违反。因此,为避免陷入局部最小值,贪心搜索算法在零层上采用回溯程序。模拟表明,至少对于低维数据(图11,d=4),获得固定召回率所需的ef参数(通过回溯期间的最小跳数决定复杂度)随着数据集大小的增加而饱和。回溯复杂度相对于最终复杂度是一个加性项,因此,根据经验数据,德劳内图近似的不准确性不会改变扩展性。
这种德劳内图近似弹性的经验研究要求德劳内图边的平均数量与数据集无关,以证明在分层NSW中如何用固定连接数很好地近似边。然而,德劳内图的平均度数随维度呈指数增长[39],因此对于高维数据(如d=128),上述条件需要极大的数据集,使得这种经验研究不可行。需要进一步的分析证据来确认德劳内图近似的弹性是否可推广到更高维空间。
4.2.2 构建复杂度
构建通过迭代插入所有元素完成,而元素的插入仅仅是不同层上K-ANN搜索序列,随后使用启发式方法(在固定efConstruction下具有固定复杂度)。元素被添加的平均层数是一个取决于mL的常数:
E[l] = E[-ln(unif(0,1))/mL] = 1/mL + 1 (1)
因此,插入复杂度与搜索复杂度相同,这意味着至少对于相对低维的数据集,构建时间的复杂度为O(N·log(N))。
4.2.3 内存成本
分层NSW的内存消耗主要由图连接的存储决定。零层每个元素的连接数为Mmax0,而其他所有层的连接数为Mmax。因此,每个元素的平均内存消耗为(Mmax0+mL·Mmax)·bytes_per_link。如果我们将元素的最大总数限制在约40亿,我们可以使用四字节无符号整数来存储连接。测试表明,接近最优的M值通常在6到48之间。这意味着索引的典型内存需求(不包括数据本身的大小)大约是每个对象60-450字节,这与模拟结果非常吻合。
5 性能评估
分层NSW算法在非度量空间库(nmslib)[49]1的基础上用C++实现,该库已经有了功能性的NSW实现(名为"sw-graph")。由于库的几个限制,为了获得更好的性能,分层NSW实现使用了自定义距离函数和C风格的内存管理,避免了不必要的隐式寻址,并允许在图遍历期间进行高效的硬件和软件预取。
比较K-ANNS算法的性能是一项非琐碎的任务,因为随着新算法和实现的出现,最先进的技术不断变化。在本工作中,我们专注于与欧几里德空间中具有开源实现的最佳算法进行比较。本文提出的分层NSW算法的实现也作为开源nmslib库1的一部分分发,同时还有一个支持增量索引构建的外部C++内存高效的仅头文件版本2。
1 https://github.com/searchivarius/nmslib
2 https://github.com/nmslib/hnsw
比较部分由四部分组成:与基线NSW的比较(5.1)、与欧几里德空间中最先进算法的比较(5.2)、重新运行NSW失败的一般度量空间中的测试子集[34](5.3)以及与大型200M SIFT数据集上最先进的PQ算法的比较(5.4)。
5.1 与基线NSW的比较
对于基线NSW算法实现,我们使用了nmslib 1.1中的"sw-graph"(与在[33, 34]中测试的实现相比略有更新),以展示速度和算法复杂度(通过距离计算次数衡量)的改进。
图12(a)展示了分层NSW与基本NSW算法在d=4随机超立方体数据上的比较,测试在Core i5 2400 CPU上进行(10-NN搜索)。分层NSW在数据集上搜索时使用的距离计算次数要少得多,尤其是在高召回率情况下。
图12(b)展示了算法在d=8随机超立方体数据集上,固定0.95召回率的10-NN搜索的扩展性。它清楚地证明了分层NSW在这种设置下具有不差于对数的复杂度扩展,并且在任何数据集大小上都优于NSW。由于算法实现的改进,绝对时间上的性能优势(图12(c))甚至更高。
5.2 在欧几里德空间中的比较
比较的主要部分是在向量数据集上进行的,使用了流行的K-ANNS基准ann-benchmark3作为测试平台。测试系统利用算法的Python绑定 - 它连续地对一千个查询(从初始数据集中随机提取)进行K-ANN搜索,使用预设的算法参数,产生包含召回率和单次搜索平均时间的输出。考虑的算法包括:
- nmslib 1.1中的基线NSW算法("sw-graph")。
- FLANN 1.8.4 [6]。一个流行的库4,包含几种算法,内置于OpenCV5。我们使用了可用的自动调优程序,进行了多次重新运行以推断最佳参数。
- Annoy6,2016.02.02构建。一个流行的算法
- VP-tree。一种一般度量空间算法,具有度量修剪功能[50],作为nmslib 1.1的一部分实现。
- FALCONN7,版本1.2。一种用于余弦相似度数据的新型高效LSH算法[51]。
比较在配备128 GB RAM的4X Xeon E5-4650 v2 Debian操作系统上进行。对于每种算法,我们在每个召回率范围内仔细选择了最佳结果,以评估可能的最佳性能(使用测试平台默认值作为初始值)。所有测试都在单线程模式下进行。分层NSW使用GCC 5.3编译,带有-Ofast优化标志。
所使用数据集的参数和描述在表1中概述。对于除GloVe外的所有数据集,我们使用了L2距离。对于GloVe,我们使用了余弦相似度,这在向量归一化后等同于L2。暴力搜索(BF)时间由nmslib库测量。
向量数据的结果在图13中呈现。对于SIFT、GloVE、DEEP和CoPhIR数据集,分层NSW明显以较大优势优于竞争对手。对于低维数据(d=4),分层NSW在高召回率下比Annoy略快,同时明显优于其他算法。
7
5.4 比较与PQ的对比
为了在大型200M SIFT数据集上进行与现有最先进的产品量化(PQ)算法的比较,我们使用了现有的C++整数距离函数实现,并支持增量索引构建10。
10 https://github.com/nmslib/hnsw
图15展示了结果,参数总结在表3中。使用linux "time –v"工具在索引构建后的单独测试运行中测量了峰值内存消耗,用于两种算法。尽管分层NSW需要明显更多的RAM,但它能够实现更高的准确性,同时在搜索速度上提供巨大的进步,并且索引构建速度更快。
图15中的插图展示了查询时间与分层NSW的数据集大小的扩展关系。注意,扩展偏离了纯粹的对数关系,这可能是由于数据集的相对较高的维度所致。
6 讨论
通过使用可导航小世界图的结构分解以及智能邻居选择启发式方法,所提出的分层NSW方法克服了基本NSW结构的几个重要问题,推进了K-ANN搜索的最新技术水平。分层NSW提供了出色的性能,并在各种数据集上都是明显的领导者,在高维数据的情况下大幅超越开源竞争对手。即使在之前算法(NSW)输给竞争对手几个数量级的数据集上,分层NSW也能够取得第一。分层NSW支持连续的增量索引,并且还可以用作获取k-NN和相对邻近图近似的有效方法,这些是索引构建的副产品。
该方法的稳健性是一个强大的特点,使其在实际应用中非常具有吸引力。该算法适用于广义度量空间,在本文测试的任何数据集上表现最佳,因此消除了为特定问题选择最佳算法的复杂性。我们强调算法稳健性的重要性,因为数据可能具有复杂的结构,在不同尺度上具有不同的有效维度。例如,数据集可以由位于随机填充高维立方体的曲线上的点组成,因此在大尺度上是高维的,而在小尺度上是低维的。为了在此类数据集中执行高效搜索,近似最近邻算法必须在高维和低维两种情况下都能良好工作。
有几种方法可以进一步提高分层NSW方法的效率和适用性。还有一个有意义的参数,它强烈影响索引的构建——每层添加的连接数M。潜在地,可以通过使用不同的启发式方法[4]直接推断这个参数。比较分层NSW在完整的1B SIFT和1B DEEP数据集[10-14]上的表现也很有意思,并添加对元素更新和删除的支持。
与基本NSW相比,所提出方法的一个明显缺点是分布式搜索可能性的丧失。在分层NSW结构中的搜索总是从顶层开始,因此由于高层元素的拥塞,该结构无法通过使用[26]中描述的相同技术来实现分布式。可以使用简单的变通方法来分布结构,例如[6]中研究的跨集群节点分区数据,但在这种情况下,系统的总并行吞吐量与计算机节点的数量扩展不佳。
然而,仍然有其他可能的已知方法来使这种特定结构分布式。分层NSW在意识形态上与众所周知的一维精确搜索概率跳跃列表结构非常相似,因此可以使用相同的技术使结构分布式[45]。由于对数可扩展性和节点上理想均匀的负载,这可能导致比基础NSW更好的分布式性能。
7 致谢
我们感谢Leonid Boytsov进行了许多有益的讨论,以及他在非度量空间库集成方面的帮助和对手稿的评论。我们感谢Seth Hoffert和Azat Davletshin对手稿和算法的建议,以及在github存储库上为算法做出贡献的同事们。我们还感谢Valery Kalyagin对这项工作的支持。
据俄罗斯基础研究基金会(RFBR)的研究项目No. 16-31-60104 mol_а _dk资助的研究报告。
Yury A. Malkov于2009年获得下诺夫哥罗德国立大学物理学硕士学位,并于2015年获得应用物理研究所RAS激光物理学博士学位。他是物理学和计算机科学20多篇论文的作者。Yury目前在莫斯科三星AI中心担任项目负责人职位。他目前的研究兴趣包括深度学习、可扩展相似性搜索、生物和人工神经网络。
Dmitry A. Yashunin于2009年获得下诺夫哥罗德国立大学物理学硕士学位,并于2015年获得应用物理研究所RAS激光物理学博士学位。从2008年到2012年,他在Mera Networks工作。他是10多篇物理学论文的作者。Dmitry目前在Intelli-Vision担任首席研究工程师职位。他目前的研究兴趣包括可扩展相似性搜索、计算机视觉和深度学习。
 陕公网安备61011302002223号
陕公网安备61011302002223号