COSMO:亚马逊的大规模电子商务常识知识生成与服务系统
COSMO: A Large-Scale E-commerce Common Sense Knowledge
Generation and Serving System at Amazon
摘要
大规模知识图谱在电子商务平台中的应用可以改善客户的购物体验。虽然现有的电子商务知识图谱(KG)整合了大量概念或产品属性,但它们未能发现用户意图,留下了与人们思考、行为和与周围世界互动方式之间的差距。在这项工作中,我们提出了COSMO,这是一个可扩展的系统,用于从大规模行为中挖掘以用户为中心的常识知识,并构建行业规模的知识图谱以赋能多样化的在线服务。
具体而言,我们描述了一个用于收集高质量种子知识断言的流程,这些断言从大型语言模型(LLM)中提取,并通过在人工参与标注数据上训练的评判分类器进一步精炼。由于这些生成的内容可能并不总是符合人类偏好且包含噪声,我们接着描述了如何采用指令调优来微调一个高效的语言模型(COSMO-LM),以实现大规模的忠实电子商务常识知识生成。COSMO-LM有效地将我们的知识图谱扩展到亚马逊的18个主要类别,仅使用30k个标注指令就生成了数百万条高质量知识。
最后,COSMO已部署在亚马逊搜索应用中,如搜索导航。离线和在线A/B实验均表明,所提出的四个系统实现了显著改进。此外,这些实验突显了从指令微调的大型语言模型中提取的常识知识的巨大潜力。
CCS 概念
计算方法论 → 知识表示与推理;• 信息系统 → 网络挖掘。
关键词
常识知识,知识图谱,大型语言模型
1 引言
理解用户在在线电子商务平台中大量嘈杂行为背后的意图,对于推荐和产品搜索等许多下游应用都是有益的[12, 21]。从认知科学的角度来看,意图是人类承诺采取行动的心理状态,行为源于意图[32]。例如,"为了参加婚礼派对,我们需要购买正装",其中意图即"参加婚礼派对"被用来合理化和解释用户行为即"购买正装"。在在线购物场景中,如果电子商务平台能够精确捕捉用户的意图,就可以变得更加智能和用户友好,提供可解释的推荐和个性化的搜索体验。
然而,这些意图并未被人类明确表达出来,这需要常识来理解,从而使机器难以以可扩展的方式提取这些意图。
最近,Yu等人[52]提出利用大型语言模型(如GPT3[2]或OPT[56])中隐式存储的大量知识,通过"询问"用户购买或共同购买产品的原因来生成用户意图。图1展示了一个示例,电子商务常识知识可以从用户行为中发现。然后,人工参与标注被用于收集判断并提供自动生成内容的人类反馈。在小规模标注数据上训练的分类器用于过滤低质量知识。这种蒸馏方法已被证明能够以较低的标注成本有效提取高精度常识知识[48, 52]。
然而,这些方法从未能很好地与人类偏好对齐的语言模型中生成知识候选。例如,我们观察到LLM可能生成既不忠实也无帮助的通用意图,如"客户一起购买它们是因为他们喜欢它们"或"客户购买Apple Watch是因为它是一种手表"。理想的生成应该是典型的,能够解释电子商务行为。使语言模型更好地遵循用户指令对于提高LLM的有用性[1, 23]、真实性[20]和透明度[31]变得至关重要。
另一方面,这种蒸馏方法仍然面临由行业级数据的可扩展性问题引起的主要挑战。首先,[52]仅基于两个类别中数千对共同购买的商品对探索共同购买意图。在真实的生产环境中,数百万用户每天产生复杂且嘈杂的行为,这些行为也潜在地包含大量且多样化的意图,例如搜索-购买行为。因此,为多样化的意图生成选择具有代表性的用户行为至关重要。其次,[52]通过分别标注合理性和典型性分数来执行细粒度标注。由于我们旨在全面支持电子商务中的更多场景,随着更多类别和更多用户行为类型的增加,标注成本显著增加。第三,当将FolkScope应用于下游任务时,推理开销可能成为瓶颈,因为新用户行为的知识生成必须经过LLM生成和分类器评分的流程。像FolkScope中使用的OPT-30b这样的LLM需要巨大的计算成本。
在这项工作中,受指令遵循语言模型最新进展的启发[4, 29, 45, 47],我们通过指令调优直接将语言模型与人类反馈对齐,用于电子商务常识知识提取。在大量数据集上进行指令微调的语言模型已经展示出卓越的零样本能力[47]。如何收集高质量且多样化的指令数据变得重要且具有挑战性。从[52]中跨两个共同购买行为领域的标注数据开始,我们在意图知识资源(即用户行为)、产品领域和关系类型方面扩展了数据收集规模,如图4所示。对于用户行为,我们还采用了行业规模的查询-商品交互来生成模糊且不断演变的意图。与共同购买行为背后的直接意图不同[52],查询意图可以帮助缩小用户真正需求与电子商务系统中产品信息呈现方式之间的语义差距。生成的意图可以帮助将宽泛的查询细化为特定用户的需求,并提高查询理解能力。此外,我们从数百万条两种用户行为数据中采样 18个热门领域(产品类别)用于知识候选生成(§3.2)。在人工标注之前,我们创建了一套启发式规则来过滤低质量知识,并设计了仔细的采样策略来选择标注候选(§3.3)。遵循Yu等人[52]的做法,我们收集了两个评估指标,分别称为合理性和典型性,作为人类反馈(§3.3.2)。为了将语言模型与人类判断相融合,我们选择典型的知识示例作为常识生成任务所期望的模型输出的演示,同时将标注标签作为标签预测任务(如典型性预测等)所期望的模型输出(§3.4)。由此产生的语言模型能够生成典型知识并判断知识质量。与原始大型语言模型相比,我们的指令微调语言模型可以显著减少推理时间,并支持大规模的广泛应用。
我们成功地在亚马逊的各种搜索应用中部署了COSMO,并在离线性能改进和在线收入增长方面取得了显著成果。
我们工作的贡献可以总结如下:
- **首个采用大型语言模型构建高质量知识图谱并服务在线应用的行业级知识系统。**我们是第一个采用大型语言模型来构建高质量知识图谱并为在线应用提供服务的行业规模知识系统。
- **采用指令调优实现有效的电子商务常识知识生成,以更好地与人类偏好对齐。**我们采用指令调优来进行有效的电子商务常识知识生成,从而更好地与人类偏好保持一致。
- **将电子商务意图知识扩展至数百万用户行为,并以更少的标注工作实现高质量指令数据生成。**我们将电子商务意图知识规模扩展到数百万用户行为,并通过更少的标注工作实现了高质量指令数据的生成。
- **将生成的意图知识应用于三个真实的电子商务任务,令人鼓舞的实验结果显示出在更多电子商务场景中的巨大潜力。**我们将生成的意图知识应用于三个真实世界的电子商务任务,有希望的实验结果显示出在更多电子商务场景中的巨大潜力。
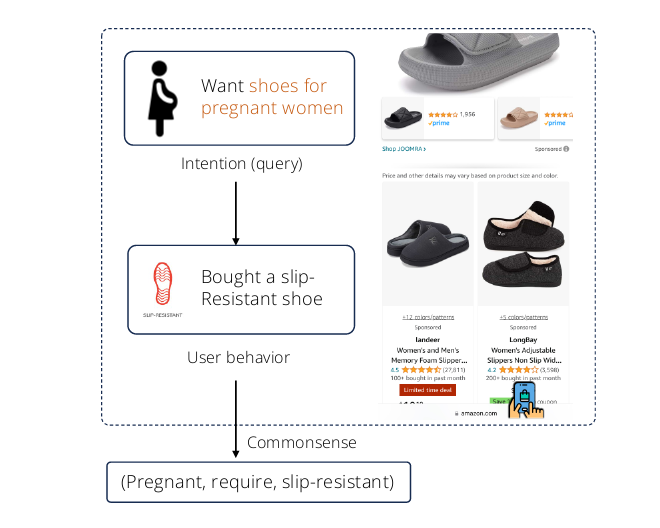
图1: 从电子商务用户行为中挖掘隐式常识知识的示例。

表1: 现有常识知识图谱之间的比较。'Rel'代表关系类型。与现有的用于意图理解的电子商务知识图谱相比,我们的新知识图谱在更多领域中涵盖了更多节点和边。
2 相关工作
**电子商务常识知识。**现有的电子商务知识图谱[5, 9, 11, 18, 19, 53, 55]主要基于关于产品属性的事实知识,例如isA或authorOf关系,并且与关于用户意图的常识知识(如"苹果产品粉丝"或"参加婚礼"等)没有很好地连接。在收集关于产品的事实知识和建模用户购买意图之间仍然存在差距,我们在表1中列出了详细的比较。相比之下,Yu等人[52]提出了一个名为FolkScope的框架,通过提示大型语言模型从大规模用户行为中提取意图知识。人类不是直接编写知识断言,而是仅将少量自动生成的内容标注为高级监督。然后,在标注数据上训练的分类器用于过滤低质量生成。尽管FolkScope以较低的标注成本实现了高精度提取,但它涵盖的领域有限,并且忽略了电子商务场景中包含复杂意图知识的大量用户交互数据类型。为了提高电子商务常识提取的泛化能力,我们扩展了FolkScope,包括扩展到18个热门领域并引入数百万搜索查询行为数据。扩展规模也在从LLM中提取知识时带来了推理效率方面的挑战[8, 41]。我们通过有效的微调来解决这些问题。
**指令遵循语言模型。**在网络规模语料库上预训练的语言模型经常生成不忠实、有偏见或无用的内容。这是因为大多数原始LM的训练目标,即预测下一个token,与人类偏好不一致。最近一系列工作表明,使用自然语言指令微调语言模型可以教导LM具有期望的模型行为[23, 47]。指令微调的LM在未见任务上的零样本和少样本性能得到了显著改善[4, 29, 45]。指令数据的质量和多样性对LM的指令遵循能力有很大影响。由于收集人工编写的指令既耗时又昂贵,Wang等人[44]提出了自指令(self-instruct)方法,基于一小组种子任务从GPT3[2]中迭代生成指令及其输出。后续工作[3, 24, 37]直接使用来自ChatGPT或GPT4的机器生成的指令遵循数据进行LLM微调。然而,他们更多地关注通用语言模型,而特定领域(如电子商务)的指令微调LM仍未被探索。我们的工作旨在实现高效的电子商务指令数据收集,并微调LLM以生成有用且典型的常识知识。
上述KG都与产品或购买意图无关。我们是第一个提出从LLM和大规模用户意图行为中构建有效KG的流程。我们的流程可以高效地为行业规模应用提供在线服务。
3 提出的框架
3.1 预备知识
在本节中,我们介绍图2中术语的正式定义以及离线COSMO知识生成流程的概述。
**用户行为。**每天有数百万用户与在线电子商务平台互动并产生大量行为日志。电子商务系统挖掘这些行为背后的意图,以提供更好的在线购物体验。我们选择了两种具有强烈潜在意图的典型用户行为,即搜索-购买和共同购买。
形式上,我们将搜索-购买行为定义为查询-产品对(q, p),即客户点击查询q并最终在短会话内购买产品p。类似地,我们使用共同购买的产品对(p1, p2)来表示共同购买行为。每个产品p可以被归类到一个主要领域d ∈ D(所有领域显示在表3和图4中)。
**常识知识。**遵循[52]的做法,我们利用关系感知提示让大型语言模型将用户行为h解释为知识候选,我们将知识表示为三元组(h, r, t),其中r和t分别代表关系和尾部。例如,"客户一起购买相机包和屏幕保护玻璃,因为它们能够为相机提供保护","为相机提供保护"是capableOf关系下的尾部。
与之前的工作[52]不同,该工作为数千条数据对齐来自ConceptNet[35]的常识关系,由于计算限制,我们无法简单地将其用于数百万用户行为对。因此,我们提出从大规模生成中进行数据驱动的关系发现,以满足电子商务场景的需求。基本思路是从四个种子关系(即usedFor、capableOf、isA、cause)开始,这些关系根据之前的工作[52]往往能生成多样化/高质量的知识,并挖掘频繁的谓词模式以手动总结关系。最常见的模式是"该产品能够被用于[介词]",其中[介词]表示介词。具有不同介词的生成代表不同的尾部类型,可以进一步规范化。通过这样做,我们还可以使生成的知识结构化。我们在表2中总结了我们挖掘的知识关系类型和相应的尾部类型以及示例。关系类型或尾部类型都更具电子商务特定性,并且与日常场景密切相关,这可能需要常识。
**指令数据。**我们将{I}表示为一组指令,其中每个指令以自然语言定义一个任务τ。图2中的一个例子可以是"使用capableOf关系为领域d中的搜索-购买行为生成解释"。每个任务包括n个输入-输出对实例。对于常识生成任务,输入可以是用户行为对(p1, p2)或(q, p),输出是典型的知识尾部t。请注意,知识(h, r, t)的质量可以通过人类标注者标注的合理性和典型性分数来衡量[25, 52]。为了可用性和有用性,我们选择具有高典型性分数的知识作为期望的模型输出。为了进一步提高指令微调模型的电子商务感知能力,我们还添加了几个辅助任务,并训练一个语言模型用于知识泛化和在线服务(更多详情见§3.4)。

图2:从大规模用户行为和LLM生成高质量指令数据的整体框架。
3.2 知识生成
在本节中,我们首先描述如何高效地采样代表性用户行为作为LLM的输入。然后我们介绍基于问答的提示,以从通用LLM中收集大规模知识候选。
**3.2.1 用户行为采样。**每天有数百万用户与在线电子商务平台互动并产生大量行为日志。在我们的工作中,我们选择了§3.1中描述的两种具有强烈潜在意图的典型用户行为,即搜索-购买和共同购买。海量行为包含噪声或是非意图性的随机行为。为了生成多样化和高质量的知识,我们进行细粒度采样,从产品采样开始,然后是行为对采样。对于产品采样,我们涵盖了亚马逊最常见的热门类别(也称为浏览节点),并选择具有相对较大行为交互的顶级产品。除了类别标签外,我们还采用产品类型标签进行采样,这些标签定义了一千多个类别并描述产品本质上是什么,例如雨伞、椅子等。
对于共同购买对采样,每个共同购买边应至少覆盖选定产品集中的一个,我们与采样对的产品类型进行交叉检查,以删除随机共同购买并避免从抽象层面重复采样。还应用了一些启发式规则,例如被不同类型产品共同购买的产品很可能是随机选择的。对于搜索-购买对采样,我们为购买率和点击率设定了经验阈值来采样查询以及购买的产品。一个关键考虑因素是查询的特异性,它表示查询是广泛的还是具体的。由于我们的目标是弥合搜索查询和产品之间的语义差距,为广泛或模糊的查询生成知识对缩小明确需求更有价值。因此,我们使用亚马逊搜索的一项内部服务来计算查询的特异性分数,并采样与购买产品相关的广泛查询。对于大多数高参与度的搜索查询,搜索引擎可以很好地理解它们的意图。我们还采样参与度较低和购买率较低的查询,以直接从LLM本身探测知识。考虑到上述所有策略,我们最终采样了数百万个行为对。采样行为对的统计数据显示在表3中,在314万个共同购买的产品对中存在140万个产品类型对,这也证明了我们采样的多样性。

| Relation Type | Tail Type | Example |
|---|---|---|
| USED_FOR_FUNC | Function / Usage | dry face |
| USED_FOR_EVE | Event / Activity | walk the dog |
| USED_FOR_AUD | Audience | daycare worker |
| CAPABLE_OF | Function / Usage | hold snacks |
| USED_TO | Function / Usage | build a fence |
| USED_AS | Concept / Product Type | smart watch |
| IS_A | Concept / Product Type | normal suit |
| USED_ON | Time / Season / Event | late winter |
| USED_IN_LOC | Location / Facility | bedroom |
| USED_IN_BODY | Body Part | sensitive skin |
| USED_WITH | Complementary | surface cover |
| USED_BY | Audience | cat owner |
| xINTERESTED_IN | Interest | herbal medicine |
| xIS_A | Audience | pregnant women |
| xWANT | Activity | play tennis |
表2:为COSMO知识图谱挖掘的电子商务常识关系。
3.2.2 QA提示生成
大型语言模型(LLM)已被证明在其参数中编码了大量知识。特定设计的提示可以使自回归LLM在语言化提示的条件下继续生成。例如,给定一个购买行为"客户购买了iPhone是因为它有",LLM可以生成与"iPhone"的功能或属性相关的意图知识。在我们的工作中,我们发现LLM更擅长在给定详细描述的场景或任务指令的情况下回答上下文化的问题,这与特定的用户行为相一致。因此,我们通过提供问答(QA)上下文来将用户行为语言化。以图3中的搜索-购买提示为例。
在末尾添加数字字符"1"是一个有用的提示工程技巧,可以生成知识候选列表。我们首先提供任务描述,如"以下搜索查询导致了以下产品购买",然后是具体的查询和产品信息。对于通用LLM,我们附加一个问题和部分答案,以便LLM可以方便地遵循给定的指令进行解析生成。在我们的工作中,我们使用托管在16个A100 GPU上的OPT175b和OPT30b[56]来进行生成推理³。附录表9中显示了每个领域的一些生成示例。

| Domain | Behavior Pairs | Annotated Candidates | Refined Edges |
|---|
表3:COSMO知识图谱的统计数据,包括采样的用户行为对、标注的知识候选以及知识精炼后剩余的边。

图3:用于生成知识候选的提示。
3.3 知识精炼
尽管通过精心设计的知识生成和特定关系解析,普通LLM仍可能生成泛化或不忠实的知识。为了鼓励多样性和有用性,我们使用以下步骤来过滤生成内容。
**3.3.1 粗粒度过滤。**在此步骤中,我们的目标是通过语言分析和适用于任何行为的通用知识来过滤不完整的生成内容。
**基于规则的过滤。**我们首先使用nltk的句子分割工具从生成内容中提取第一句话。然后我们基于GPT-2语言模型计算困惑度分数,并调整阈值以删除不完整的句子。我们还直接过滤与查询、产品类型或产品标题完全相同的生成内容(或编辑距离小于阈值)。对于"用于相同原因"或"与衣服一起使用"等通用知识,我们通过结合频率和熵来识别这些情况,因为它们与许多产品或查询共同出现,而不是特定的产品或查询。
**相似度过滤。**为了处理在前一步骤中无法轻松处理的语义相似情况,我们使用内部语言模型来获取生成知识尾部、查询和产品本身的嵌入向量。该模型在电子商务语料库(包括查询、产品信息等)上进行了预训练。知识嵌入与上下文嵌入(原始查询或产品嵌入)之间的相似度通过其余弦相似度计算:
sim(𝑘, 𝑐) = cos(E(𝑘), E(𝑐)). (1)
我们发现被过滤的生成内容本质上是原始用户行为上下文通过句法转换后的释义。通过两个粗粒度过滤步骤,我们能够去除相当大量的噪声,并尽可能保留典型知识。

图4:微调COSMO-LM以从两种典型用户行为中生成电子商务常识知识的示意图。我们扩展了产品领域、关系类型和任务。
3.3.2 人工参与标注
标注步骤旨在为知识候选提供人工反馈并收集多样化的指令数据。最大的挑战仍然是在大量知识候选和成本之间取得平衡。我们期望在标注数据上训练的模型能够在表3所示的多个类别中良好泛化。均匀采样可能会损害长尾知识的预测性能。相反,我们结合知识频率的对数和产品或查询的流行度进行重新加权:
𝑤(𝑘, 𝑐) = log(𝑓(𝑘)) / (pop(q) × pop(p)), (2)
其中𝑓(𝑘)是生成知识的频率,流行度函数由查询-产品交互图中查询的度或产品共同购买图中产品的度定义。产品越流行,生成的知识越可能是通用的。对于这两种用户行为,我们各采样了1.5万个知识候选进行标注,分布也显示在表3中。
由于数据隐私问题,我们聘请专业数据标注供应商公司进行高质量标注,随后进行严格和仔细的内部审核流程。先前的工作[52]通过两步标注来衡量生成知识的质量,即合理性(知识的合理程度)和典型性(知识对典型购物行为的代表性)。一个例子是,客户购买Apple Watch的更典型意图是它们是智能手表,而不是用于报时。为了减轻标注者的认知负担和常识的潜在分歧率,我们将这两个测量的判断分解为五个明确的问题:1)解释是否为完整句子?2)解释是否相关?3)解释是否信息丰富?4)解释是否合理?5)解释是否典型?,其中每个问题由两位不同的标注者标记为是/否/不确定,如果发现分歧则由第三人最终检查⁴。对2000个样本标注的试点研究表明,该流程显著降低了分歧率。对于标注数据的质量,我们随机抽样5%的标注进行内部审核,准确率可达90%以上。然后我们使用这些数据构建分类模型,对粗粒度过滤后的所有知识候选进行评分。我们对DeBERTa-large[6]和我们的内部语言模型进行微调,将人工判断推广到所有知识候选,并保留合理性分数高于0.5的候选。经过知识精炼过程,我们以相对较低的成本获得了高质量的电子商务知识,统计数据也显示在表3中。
表4:两种用户行为的标注数据的合理性和典型性比率。
| Plausibility | Typicality |
|---|---|
| Search-buy 44.3% | 35.0% |
| Co-buy 14.5% | 9.0% |
3.4 指令微调的COSMO语言模型
在收集了30k个多样化知识样本的人工判断后,我们可以基于标注数据创建大规模指令数据。标注结果如表4所示。我们可以观察到,超过三分之一的搜索-购买生成是典型的,可以直接作为指令数据使用。但共同购买的典型比率明显较低,因为LLM主要为其中一个共同购买的产品生成意图知识,而不是考虑它们的共同原因,使得生成内容不合理。我们期望微调的语言模型具有期望的模型行为。除了生成典型知识,我们使LM具有合理性和典型性预测的能力,其中所有标注都转换为任务的指令数据。
考虑到用户行为数据存在不可忽视的噪声,我们在§3.3.2中的细粒度标注已经识别出不相关的查询-产品对或随机共同购买对。我们还考虑将共同购买预测和搜索相关性预测添加到微调任务中。到目前为止,我们收集的指令数据涵盖了18个产品领域、15种关系类型和5种不同类型的任务。为了使模型对不同格式具有鲁棒性,我们设计了不同的模板来语言化指令和输入-输出对。例如,我们添加"搜索查询"、"用户输入"或"用户搜索了:"等前缀。我们使用收集的指令数据微调LLaMA 7b和13b模型[38, 39],这些是广泛使用的开放基础模型。

图5:COSMO-LM部署示意图,以异步缓存存储和特征存储为中心组件。它描述了用户查询的高效处理和动态每日更新,这对于满足亚马逊的搜索延迟要求至关重要。
3.5 在线部署
部署以高效的特征存储和异步缓存存储为中心,确保流畅处理和经济高效地管理客户查询和模型响应。
3.5.1 部署策略
**部署管理:**使用SageMaker[14]5来刷新COSMO-LM模型,通过强大的自动化功能促进客户行为会话日志的动态接入和高效的模型更新。**特征存储集成:**该存储对于将模型响应转换为结构化特征至关重要,使其可用于下游应用。它处理产品键值对、语义子类别表示和强意图检测等特征。**异步缓存存储:**用于管理频繁搜索并适应每日流量模式,该存储通过双层缓存策略高效捕获用户查询,结合预加载的年度频繁搜索和批处理的每日请求。
3.5.2 操作流程
我们列出了图5所示的关键流程:
- **模型部署:**COSMO-LM部署在SageMaker上,用于处理用户行为会话日志和动态模型更新。
- **请求处理:**初始查询检查异步缓存存储,快速检索频繁查询的响应或将其他查询转发进行批处理。
- **批处理和缓存更新:**特征存储将语言模型响应格式化为结构化洞察,更新缓存以供未来查询使用。
- **与下游应用的通信:**来自缓存的结构化数据增强了各种下游应用,为改善用户交互提供了丰富的特征。
- **反馈循环:**通过将用户交互反馈到COSMO-LM中来实现持续的模型精炼,确保对不断演变的用户行为保持最新的响应能力。
3.5.3 影响与局限性
COSMO-LM的部署利用异步缓存存储和特征存储策略,有效满足了亚马逊严格的搜索延迟要求,同时对大部分流量保持与实时服务相当的存储成本。这种方法显著增强了我们快速且经济地管理在线请求的能力。需要承认的是,尽管我们每天刷新模型,但我们在处理实时信息(如限时抢购)方面受到限制。这些时间敏感的事件通常在短时间内波动,对我们当前系统快速吸收和反映这种即时变化的能力构成挑战。这一局限性凸显了进一步开发的必要性,以增强我们系统在应对电子商务活动快节奏动态方面的敏捷性。
4 评估与应用
在本节中,我们采用经过指令微调的COSMO语言模型为下游应用生成电子商务常识知识,即搜索相关性、基于会话的推荐和搜索导航。我们进行了广泛的离线和在线评估实验,以证明我们提出的框架和部署系统的有效性。
4.1 搜索相关性
确定搜索查询与文档之间的相关性分数是信息检索的核心,它是搜索引擎的关键组成部分[34]。电子商务产品搜索的一个主要挑战是查询与产品目录之间的语义差距[13, 22]。其中一些需要丰富的常识知识来将它们连接起来。例如,查询"冬季服装"通常暗示用户想要保暖的衣服。因此,我们使用解释搜索-购买行为的COSMO知识来增强搜索相关性预测。
形式上,给定查询 = {1, 2, ..., }和检索到的产品列表,其中 ∈ ,排名或分类任务都需要每个查询-产品对{, }的相关性分数[26]。在真实的电子商务系统中,每个产品都伴随着附加信息,例如产品标题、描述和属性。为简单起见,我们将它们连接成一个单一的文本片段 = {1, 2, ..., }。如前所述,查询中的用户意图与产品信息之间仍然存在语义差距,我们利用COSMO-LM生成查询-产品对背后的常识知识 = {1, 2, ..., },并明确增强它们之间的联系。
4.1.1 实验设置
我们采用KDD Cup 2022公开发布的亚马逊购物查询数据集⁶。遵循任务2的设置,衡量搜索相关性的问题被表述为一个四类分类问题:将给定产品区分为用户查询的精确匹配、替代品、补充品或不相关匹配。为了验证我们方法的泛化能力,我们还从在线系统中收集了类似的数据集,以适应不同市场的产品多样性和语言习惯,即美国(us)、加拿大(ca)、英国(uk)和印度(in)。数据集统计数据见表5。考虑到类别不平衡分布,我们报告宏F1和微F1,但更关注前者。

图6:搜索相关性模型示意图。

表5:不同地区(市场)的ESCI评估数据集统计信息。
4.1.2 基线模型
我们考虑图6所示的两种代表性架构作为基线:
- 双编码器[27, 33],也称为双塔模型,将查询表示和产品标题表示的连接作为多层感知器的输入来预测相关性标签。
- **交叉编码器[49]**将所有相关特征(例如查询、产品标题、描述等)输入到统一编码器中,并利用联合表示进行预测。
由于额外的注意力交互,交叉编码器模型通常优于双编码器模型。因此,我们使用生成的知识特征来增强交叉编码器模型,即将[q, p, k]连接作为输入。我们遵循[49]使用强大的deberta-v3-large⁷作为基础模型,并考虑编码器的固定和调优设置。
4.1.3 公共数据集结果
表6显示,从COSMO-LM生成的知识捕获了隐式的电子商务常识,可以显著提升查询-产品语义相关性的性能。当编码器固定时,两种架构之间没有巨大差异。但增强的意图知识使宏F1的性能提升了约60%,微F1提升了约30%。当编码器的参数被更新时,我们仍然可以观察到约25%的性能提升。最终,生成的知识帮助交叉编码器达到了73.48%的宏F1和90.78%的微F1,甚至超过了KDD Cup排行榜上的第一名集成模型[49]。
4.1.4 私有数据集结果
为了进一步验证我们的方法在多地区场景中的有效性,我们在大规模私有数据集上进行了类似的实验。不同地区(市场)的产品分布和查询语言习惯可能存在显著差异。我们期望生成的知识能够为搜索相关性系统提供高质量的特征或信号,并推广到更复杂的场景。从图7a和图7b,我们可以得出以下观察结果:1). 我们的COSMO-LM即使在标注有限的情况下也能始终帮助增强交叉编码器性能,这与§4.1.3中公共数据集的结果一致。2). 无论编码器是固定还是调优,意图增强的交叉编码器模型在所有地区都能显著优于基线方法。

4.2 基于会话的推荐
推荐系统已成为电子商务平台中最关键的组成部分之一,帮助客户从海量且快速增长的产品中进行选择。与一段时间内多个用户-物品交互相关联的会话,除了用户画像之外,还能更好地捕获用户偏好和意图[10, 16, 42, 43]。基于会话的推荐通常从产品物品集合 = {1, 2, ..., }中预测下一个点击或购买的物品,给定按时间顺序排列的匿名行为序列 = {1, 2, ..., },其中 是会话 的长度。序列神经网络,如RNN[7]、transformers[36],被用来捕获会话内的用户动态偏好。此外,物品序列可以组织为会话图G = (V, E),使用图神经网络对相邻物品的复杂成对交互进行建模。边(, )的关系可以通过交互方向定义,即入边或出边[46]。无论是序列方法还是基于图的方法都只学习 的物品嵌入,而忽略了产品的辅助信息,如产品标题、产品属性和交互模式。其中,与点击/购买行为相关的搜索查询有助于更好地捕获用户意图和不断演变的偏好变化。因此,我们通过辅助用户搜索关键词序列 = {1, 2, ..., }和我们为每个搜索-产品对(, )生成的知识来改进基于会话的推荐。
4.2.1 实验设置
我们从日志系统中收集并过滤了一周的会话数据,这些数据属于服装和电子产品类别。每个会话限制在20分钟内,包含同一领域中的高频物品,并以成功购买结束。对于训练/测试划分,前五天的会话用作训练,第六天和最后一天用作验证和测试数据。数据集统计信息详见表7。电子产品领域的会话比服装拥有更长的唯一查询序列。这表明用户可能会修改他们原始的搜索关键词,对用户查询动态进行建模有助于精确预测用户行为。我们将基于会话的推荐表述为排名问题,如之前的工作[43],并在实验中采用常用指标,即Hits@10、NDCG@10和MRR@10。
4.2.2 基线模型
我们与具有竞争力的序列模型和基于图的模型作为基线进行比较:
- FPMC[28] 通过基于马尔可夫链的方法来表示会话。
- GRU4Rec[7] 利用门控循环单元(GRU)来模拟马尔可夫决策过程,但具有更好的泛化能力。
- STAMP[15] 对最后一个物品和先前历史应用注意力机制来表示用户的短期兴趣。
- CSRM[40] 结合内部记忆编码器和外部记忆来捕获会话相关性。
- SR-GNN[50] 是第一个将图神经网络(GNN)应用于基于会话的推荐(SBR)任务的方法,它将会话序列转换为有向无权图以学习物品和转换表示。
- GC-SAN[51] 通过在图卷积后对整个图进行自注意力来扩展SR-GNN,以获得全局表示。
- GCE-GNN[46] 使用软注意力从会话图和全局图聚合两个级别的物品嵌入。
4.2.3 COSMO-GNN
初步实验表明,GCE-GNN可以在各种基于会话的推荐数据集上实现强大的性能,并通过两级GNN学习更好的物品嵌入。因此,我们使用从COSMO-LM生成的与搜索查询相关的知识来扩展GCE-GNN,并联合优化GNN以实现搜索意图感知推荐。我们将所提出的方法命名为COSMO-GNN。形式上,对于时间步

在会话中的时间步 t,用户搜索查询 qt 并与物品 vt 进行交互。从 GCE-GNN 获得的物品嵌入表示为 ht。然后使用 COSMO-LM 生成意图知识,解释查询-产品对 (qt, vt) 的行为。我们利用相同的语言模型对生成的知识进行向量化,并获得会话知识嵌入 gt。为了将知识空间与 GNN 特征空间对齐,使用两层感知器将知识表示 gt 转换为 ĝt。每个步骤的最终表示是 GNN 物品嵌入和知识嵌入的连接,即 [ht, ĝt]。遵循 [46],会话表示可以通过对所有步骤表示的平均池化来获得。
4.2.4 实验结果
实验结果如表8所示。我们可以观察到:1). 我们提出的 COSMO-GNN 在两个领域的 Hits@10 和 NDCG@10 上显著优于所有竞争基线,并且在 MRR@10 上几乎超越所有基线。2). COSMO-GNN 在具有更复杂和多样化搜索序列的会话数据上获得了略多的改进(Hits@10 为 5.82% 对比 4.05%)。如表7所示,电子产品会话中涉及的唯一搜索查询比服装多(2.47 对比 1.36)。原因可能是服装的用户意图更容易描述,但需要更多的背景知识来进行修订以达到用户真正需要的内容。关于 COSMO 如何减少查询重写等更多研究留待未来工作。
SIGMOD-Companion '24, June 9–15, 2024, Santiago, AA, Chile Yu, et al.
4.3 搜索导航
除了上述传统电子商务场景 [17, 54] 外,COSMO 还能彻底改变搜索导航,从传统的以产品为中心的分类法转向以客户为中心的方法。这种转变增强了购物体验,使其更紧密地与客户意图和行为保持一致,并通过动态提供带有客户查询概念的分类法,弥合产品分类与客户语言之间的差距。具体而言,COSMO 的意图知识可以进一步组织成如图8所示的层次结构,将粗粒度概念(露营)扩展到细粒度概念(冬季露营),意图概念进一步与产品概念(如冬季靴子)相链接。

图8:COSMO尾部知识层次组织的示意图。
4.3.1 多轮导航
COSMO以其多层次和动态的导航系统而独树一帜(图9):
- 广泛概念解释: 它首先通过高级分析和客户行为洞察来处理广泛的查询,涵盖广泛的用户意图,而无需明确的领域知识。
- 产品类型和子类型发现: COSMO随后帮助用户识别特定的产品类型和子类型,擅长处理直接和抽象的产品查询。
- 基于属性的精炼: 最后一层有助于微调搜索结果,允许用户根据特定属性进行过滤,并使结果与个人偏好保持一致。
COSMO功能的核心是多轮导航。在这里,COSMO擅长通过持续推荐提供多轮搜索精炼。例如,搜索"露营"可能会导致选择充气床垫,然后精炼为露营充气床垫。COSMO随后会提供各种类型的露营充气床垫,以满足不同的需求,例如湖边露营、山地露营或4人露营。这种多轮导航允许进行更深入和更精确的精炼,反映了自然的发现过程,并显著增强了用户的搜索体验。

图9:使用COSMO的搜索导航体验
4.3.2 在线实验
将COSMO集成到我们的在线搜索导航系统中带来了显著的业务改进,凸显了基于COSMO-LM应用的力量和潜力。这一结论来自精心进行的亚马逊在线A/B测试,总共进行了几个月,针对约10%的亚马逊美国流量。这些结构良好的测试显示,该细分市场中的产品销售额相对增长了0.7%,相当于每年数亿美元的收入激增。此外,在同一流量细分市场中观察到导航参与率增加了8%,突显了客户互动和满意度的提高。
考虑到这些结果是从在搜索页面上实施单个相对较小的功能得出的,并且如图9所示,展示空间有限,这些结果尤其重要。这一初始实施的成功表明了巨大的机会:通过将COSMO-LM的适应扩展到涵盖所有导航流量,我们预计有潜力产生数十亿美元的收入增长。此外,这一有希望的结果还强调了在各种其他功能和应用中利用COSMO-LM的巨大潜力,为增强用户体验和业务增长开辟了新途径。

图10:COSMO-LM生成示例
5 结论
在本文中,我们提出在一组电子商务标注数据(以指令形式表达)上微调语言模型,以生成符合人类偏好的高质量常识知识。为了收集大规模和多样化的指令数据,我们设计了一个基于海量用户行为的自动指令生成流程。扩展产品领域、关系类型和微调任务实现了可扩展的知识提取。此外,下游应用(如语义相关性和基于会话的推荐)证明了从指令微调语言模型生成的知识的有效性。与直接从大型语言模型中提取知识相比,参数更少的指令微调模型在模型推理效率方面具有显著优势。我们的工作代表了将语言模型与特定领域人类偏好对齐的第一步,我们部署的知识系统已经取得了显著的业务影响。
致谢
Yangqiu Song得到了香港研究资助局的RIF(R6020-19和R6021-20)以及GRF(16211520和16205322)的支持。Yangqiu Song感谢来自UGC研究配对资助(RMGS20EG01-D、RMGS20CR11、RMGS20CR12、RMGS20EG19、RMGS20EG21、RMGS23CR05、RMGS23EG08)的支持。
 陕公网安备61011302002223号
陕公网安备61011302002223号